


Multimodal retrieval models are revolutionizing how AI understands and processes data combining text and images. While CLIP (Contrastive Language-Image Pre-training) laid the foundation, newer models like
Visualized BGE (Bootstrapped Grid Embedding)
VISTA (Visualized Text Embedding for Universal Multimodal Retrieval)
MagicLens by Google
are advancing the field by addressing CLIP’s limitations and pushing the boundaries of what’s possible in multimodal AI.
In this post, we’ll explore the detailed architectures and training techniques of CLIP, Visualized BGE, VISTA, and MagicLens, explaining how each model works, the improvements they bring, and the future direction of multimodal search.
1. CLIP: The Foundation of Multimodal Learning

What is CLIP?
CLIP, developed by OpenAI, is a model designed to understand and relate images and text through contrastive learning. It learns to match images with their corresponding text descriptions and to differentiate these pairs from mismatches, enabling it to perform various tasks, from image classification to zero-shot learning.
How Does CLIP Work?
Contrastive Learning: CLIP is trained on a vast dataset of image-text pairs, learning to create a shared embedding space where both images and texts are represented as vectors. The model maximizes the similarity of correct image-text pairs and minimizes it for incorrect pairs.
Joint Embedding Space: CLIP’s ability to create a joint embedding space for images and text allows it to generalize across different tasks and domains.
Limitations of CLIP
Fine-Grained Visual Understanding: CLIP struggles with fine-grained visual details due to its broad learning approach. It can miss subtle distinctions within images that are critical for certain tasks.
Imprecise Multimodal Alignment: The alignment between text and images can be imprecise, especially when dealing with complex or nuanced relationships.
Retrieval Performance Variability: CLIP's performance can vary depending on the specificity of the query and the image, sometimes leading to suboptimal results.
2. Visualized BGE: Enhancing Visual Precision
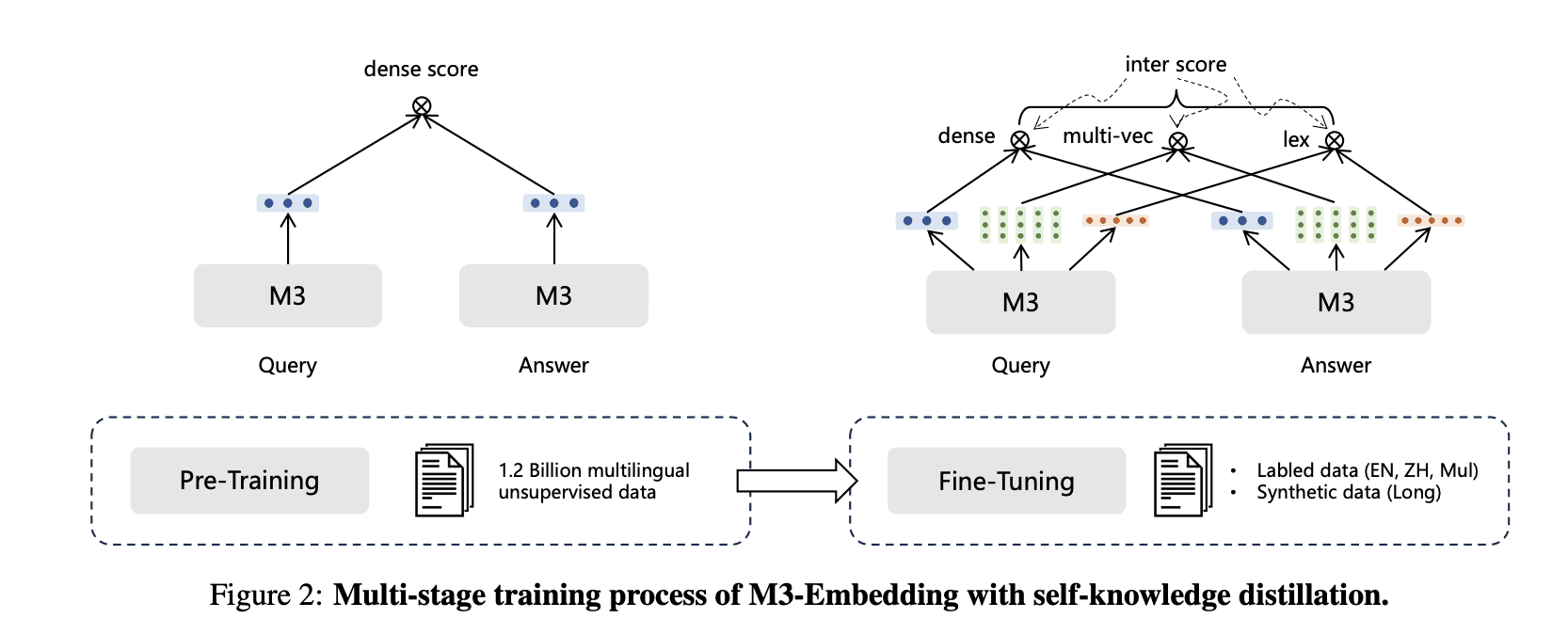
What is Visualized BGE?
Visualized BGE introduces a refined approach to embedding visual information, particularly focused on capturing fine-grained details within images. The model, developed under BAAI, includes the BGE-Visualized-M3 variant, which takes this technology further by integrating advanced retrieval functionalities. This model builds upon the foundation laid by CLIP but adds significant improvements in how visual data is processed and understood.
How Does Visualized BGE Work?
Grid-Based Embeddings: Unlike CLIP, which processes entire images, Visualized BGE (specifically the BGE-Visualized-M3 variant) breaks down images into grids and embeds each segment separately. This grid-based approach allows the model to capture more localized and detailed visual information.
Bootstrapping: Visualized BGE uses a bootstrapping process where the model iteratively refines its understanding of the image’s content. This iterative training enhances the model's ability to differentiate between subtle visual details.
Leveraging Stable Diffusion: The training process of Visualized BGE, especially in its M3 variant, incorporates techniques similar to stable diffusion to generate edited images. These variations expose the model to a diverse set of images, thereby improving its ability to recognize and embed fine-grained details across various scenarios.
Prominent Example - BGE-Visualized-M3
The BGE-Visualized-M3 model is a prominent example of the Visualized BGE architecture. It supports multiple retrieval functionalities such as:
Dense Retrieval: Standard dense retrieval, commonly seen in text embeddings.
Multi-Vector Retrieval: Fine-grained interactions between multiple vectors.
Sparse Retrieval: Term-based retrieval with enhanced importance assigned to certain terms.
Advantages of Visualized BGE
Fine-Grained Detail Recognition: The grid-based embedding method enhances the model’s ability to recognize and differentiate fine details within images.
Improved Retrieval Accuracy: The detailed focus leads to more accurate retrieval results, particularly in scenarios where specific visual features are critical.
Complex Image Handling: Visualized BGE, especially in its BGE-Visualized-M3 variant, excels in understanding complex images with multiple elements, where generalist models like CLIP might struggle.
3. VISTA: Revolutionizing Multimodal Retrieval

What is VISTA?
VISTA (Visualized Text Embedding for Universal Multimodal Retrieval) takes the advancements of Visualized BGE even further by enhancing the integration of text and image data. VISTA introduces a sophisticated method of embedding text in a way that is deeply integrated with visual data, making it a versatile model for a broad range of multimodal tasks.
How Does VISTA Work?
ViT and Text Tokenization: VISTA uses a Vision Transformer (ViT) as an image tokenizer, feeding the visual tokens into a pre-trained text encoder. This allows the model to handle images, text, and multimodal data seamlessly.
In-Depth Fusion: VISTA creates a deeply fused multimodal representation by concatenating the visual tokens from the ViT encoder with the text tokens and processing this interleaved sequence through a frozen text encoder. This ensures that the text embedding capabilities are preserved while enhancing image-text alignment.
Two-Stage Training Process: VISTA employs a two-stage training process. In the first stage, it performs cross-modal training using massive weakly labeled data, aligning visual tokens with the text encoder. In the second stage, VISTA fine-tunes this alignment with high-quality composed image-text datasets, significantly improving the model's ability to handle complex multimodal tasks.
Improvements Over CLIP
Unified Embedding Space: Unlike CLIP, which handles text and image embeddings separately, VISTA creates a unified embedding space that ensures better integration and alignment of text and image data.
Versatility: VISTA’s architecture allows it to excel across a broader range of multimodal retrieval tasks, from simple image-text matching to complex multimodal document retrieval.
Enhanced Detail and Context Understanding: By deeply integrating visual and textual data, VISTA can better understand and retrieve information based on nuanced and detailed queries.
4. MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions

What is MagicLens?
MagicLens is a cutting-edge, self-supervised image retrieval model designed to handle open-ended instructions for image search. Unlike traditional models that focus on visual similarities, MagicLens allows users to express complex search intents through natural language, retrieving images based on diverse semantic relations beyond mere visual features.
How Does MagicLens Work?
Training on Web Data: MagicLens is trained on 36.7 million image triplets (query image, instruction, target image) mined from naturally occurring web image pairs. These pairs contain implicit relations (e.g., “inside view of,” “different angle”), which are made explicit using large multimodal models (LMMs) and large language models (LLMs).

Self-Supervised Learning: The model generates diverse instructions using foundation models (PaLM and PaLI) and learns to align image-text pairs via contrastive learning, allowing it to support open-ended, complex queries.
Dual-Encoder Architecture: A dual-encoder system processes the query image and integrates the instruction into the target image retrieval, making the system highly efficient for diverse retrieval tasks.
Key Innovations:
Beyond Visual Similarity: MagicLens excels at retrieving images based on non-visual relations, such as context, object-specific queries, or semantic differences (e.g., “different product angle” or “related landmarks”).
Efficient Model Size: Despite being 50x smaller than previous state-of-the-art models, MagicLens achieves superior performance across various image retrieval benchmarks.
Real-Time and Accurate Retrieval: MagicLens allows for interactive, real-time search and refines results based on user feedback, making it adaptable to dynamic retrieval tasks.
Why It’s an Advancement:
MagicLens moves beyond the visual similarity limitations of CLIP and Visualized BGE, supporting open-ended, natural language-driven searches. It represents a significant leap in the ability to handle complex, contextually rich image queries, making it highly effective and scalable for modern multimodal search applications.
5. The Future of Multimodal Search: Beyond Visualized BGE, VISTA, and MagicLens
The advancements in Visualized BGE, VISTA, and MagicLens represent significant steps forward in multimodal retrieval, but the field is rapidly evolving. As we look to the future, several trends and directions are emerging:
Deeper Multimodal Fusion: Future models will likely push even further in fusing modalities, moving beyond just text and images to include audio, video, and other data types, creating even more powerful and versatile AI systems.
Personalized and Contextualized Retrieval: The next wave of multimodal models will focus on personalizing search results based on user context and preferences, making retrieval more relevant and tailored to individual needs.
Scalable and Efficient Models: As the complexity of multimodal data increases, there will be a greater focus on building models that are not only powerful but also efficient and scalable, capable of handling vast amounts of data without compromising performance.
Conclusion
CLIP laid the foundation for modern multimodal retrieval, but the emergence of Visualized BGE, VISTA, and MagicLens represents a leap forward in this field. By addressing the limitations of CLIP, these models offer improved accuracy, better integration of text and visual data, and greater versatility across a range of tasks. As multimodal AI continues to evolve, the innovations introduced by Visualized BGE, VISTA, and MagicLens will likely serve as a blueprint for the next generation of models, driving the future of search and retrieval technology into new and exciting territories.


