


Welcome to the realm of Florence-2, Microsoft Azure AI's trailblazing model in computer vision. This comprehensive guide delves into Florence-2's innovative approach, setting a new standard in vision AI with its unified, prompt-based architecture for a broad spectrum of vision and vision-language tasks.
A New Approach: Rethinking Vision Model Pre-training
Pioneering Universal Representation Learning
Florence-2 represents a paradigm shift in vision model pre-training. Moving beyond the constraints of traditional supervised, self-supervised, and weakly supervised learning paradigms, Florence-2 brings a unified approach to tackle a wide array of vision tasks using a single model architecture. This shift addresses the need for adaptability and a comprehensive understanding of visual data beyond single-task learning frameworks.
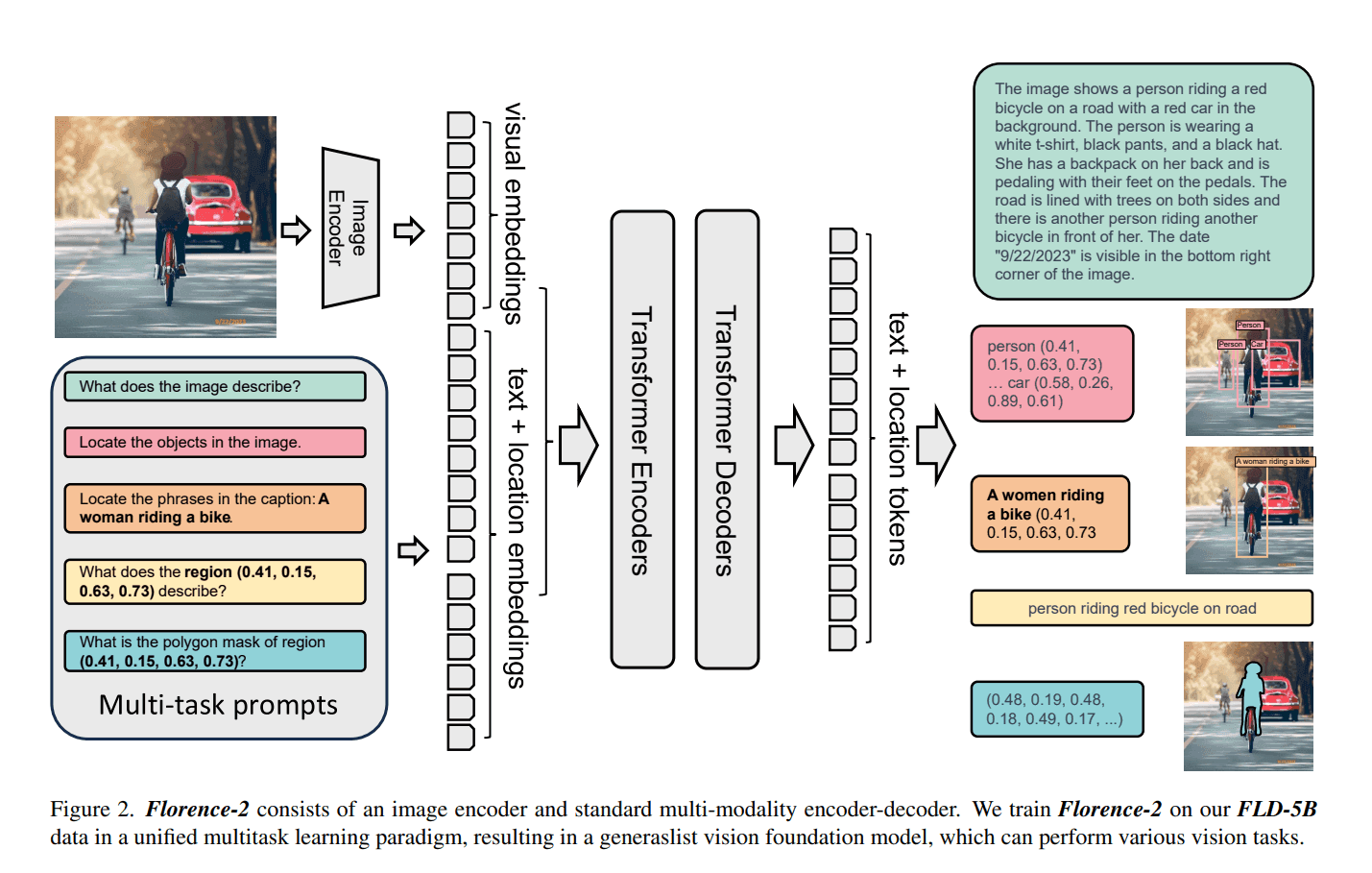
Comprehensive Multitask Learning with Florence-2
Mastering Spatial and Semantic Granularity
Florence-2's comprehensive multitask learning objectives are designed to address various aspects of visual comprehension, aligning with spatial hierarchy and semantic granularity. It incorporates image-level understanding tasks for high-level semantics, region/pixel-level recognition tasks for detailed object localization, and fine-grained visual-semantic alignment tasks. This multifaceted approach enables Florence-2 to handle different levels of detail and semantic understanding, ultimately learning a universal representation for vision.
Inside Florence-2: Unifying Vision and Language
The Power of Sequence-to-Sequence Learning
Florence-2 employs a sequence-to-sequence learning paradigm, integrating tasks under a common language modeling objective. It takes images coupled with text prompts to generate text-based results. This structure allows Florence-2 to handle various vision tasks in a unified manner, from image classification to complex captioning and visual grounding.
Data Engine: The Foundation of Florence-2
Building a Large-Scale Multitask Dataset
To train Florence-2, a comprehensive dataset named FLD-5B was developed. This dataset includes 126 million images with over 500 million text annotations, 1.3 billion text-region annotations, and 3.6 billion text-phrase-region annotations. The diversity and scale of FLD-5B provide a rich foundation for Florence-2 to learn and excel across various vision tasks.
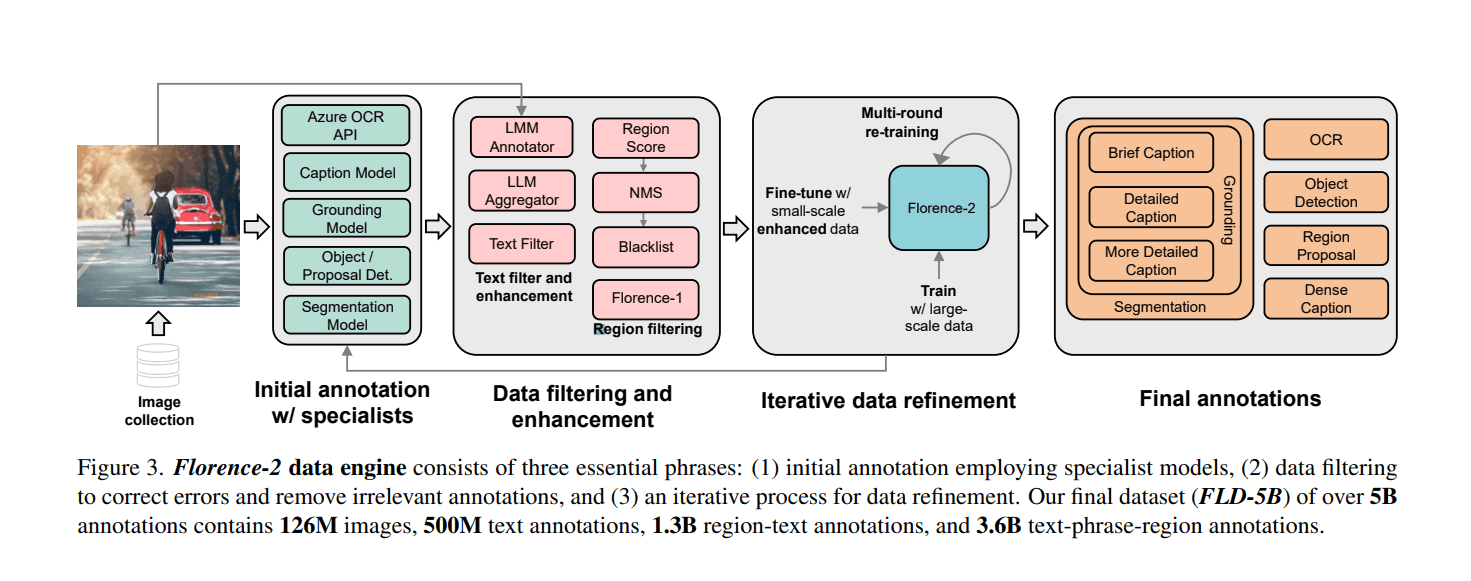
Dataset Analysis: Understanding FLD-5B
Exploring the Depth of Annotations
FLD-5B sets itself apart with its detailed annotation statistics, semantic coverage, and spatial coverage. Each image in FLD-5B is annotated with text, region-text pairs, and text-phrase-region triplets, offering diverse levels of granularity. This enables more comprehensive visual understanding tasks and positions FLD-5B ahead of existing datasets used for training foundation models.
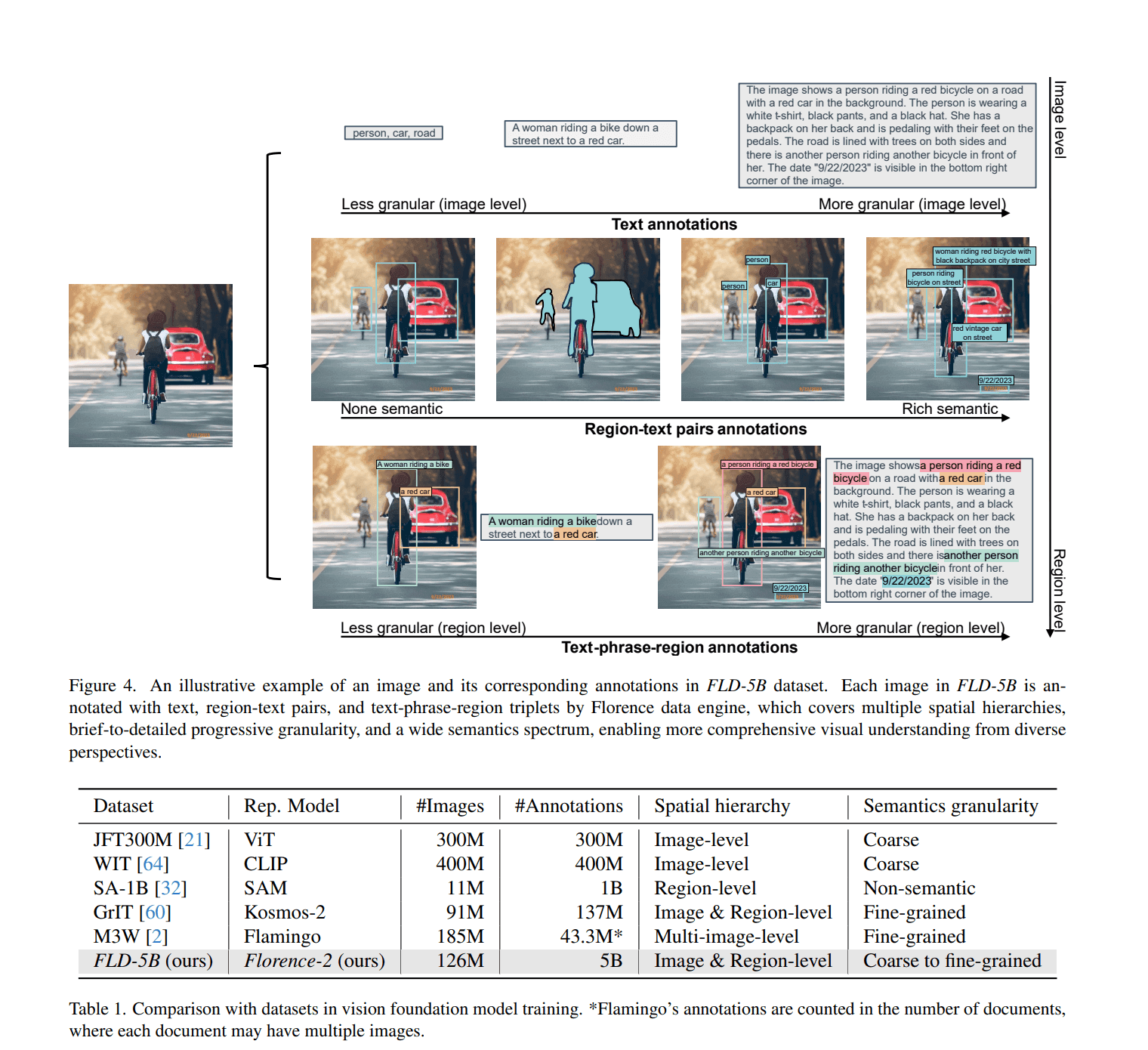
Experiments with Florence-2: Proving Its Mettle
Demonstrating Versatility and Advanced Performance
Florence-2's training on FLD-5B enabled it to learn a universal image representation. The experiments conducted on Florence-2 encompassed evaluating its zero-shot performance, adaptability with additional supervised data, and performance in downstream tasks. These tests proved Florence-2's ability to handle multiple tasks without extra fine-tuning, achieving competitive state-of-the-art performance, and demonstrating the superiority of its pre-training method over previous approaches.
Zero-Shot Evaluation: Florence-2's Impressive Versatility for Handling Unseen Tasks
In an exciting part of the research, Florence-2 was put through a "zero-shot" evaluation. This test was all about seeing how well the model could handle tasks it wasn't directly trained to do. Here's what stood out:
Remarkable Image Understanding: On the COCO caption benchmark, a standard test for image understanding, Florence-2-L (a larger version of the model) scored impressively high. It did this using far fewer parameters than much larger models, showcasing its efficiency.
Excelling in Complex Tasks: For more detailed tasks like understanding and describing specific regions in images, Florence-2-L not only did well but set new records in performance. This shows its ability to grasp complex visual details.
General Versatility: The model demonstrated strong adaptability across various types of tasks, from image captioning to answering questions about images, without needing special training for each.
This zero-shot evaluation reveals that Florence-2 isn't just good at the tasks it's trained for; it's also quick to adapt to new challenges. This versatility makes it a standout model, ready for a wide range of real-world applications.
Here's a breakdown of the downstream tasks fine-tuning experiment with Florence-2:
Choice of Model: For these tests, they used a smaller version of Florence-2 with about 80 million parameters. This choice was made to ensure a fair comparison with other similar models.
Selected Tasks for Testing:
Object Detection and Segmentation: The team tested Florence-2 on two key tasks using the COCO dataset. These tasks were:
Object detection and instance segmentation with a method called Mask R-CNN.
Object detection with another method known as DINO.
Training and Evaluation Details:
The model was trained using images from the COCO dataset's 2017 training set and then evaluated using the dataset's 2017 validation set. For the Mask R-CNN method, they followed a standard training schedule without any additional tricks or techniques. This straightforward approach meant that any success could be attributed to Florence-2’s pre-training. Similarly, for the DINO method, the team kept the training simple and standard, focusing on demonstrating the model's inherent capabilities.
What They Found:
The results were quite remarkable. Despite the simplified training approach, Florence-2 performed exceptionally well in these specific tasks.
This success indicated that the comprehensive pre-training of Florence-2 had effectively prepared it to handle complex and varied visual tasks with ease.
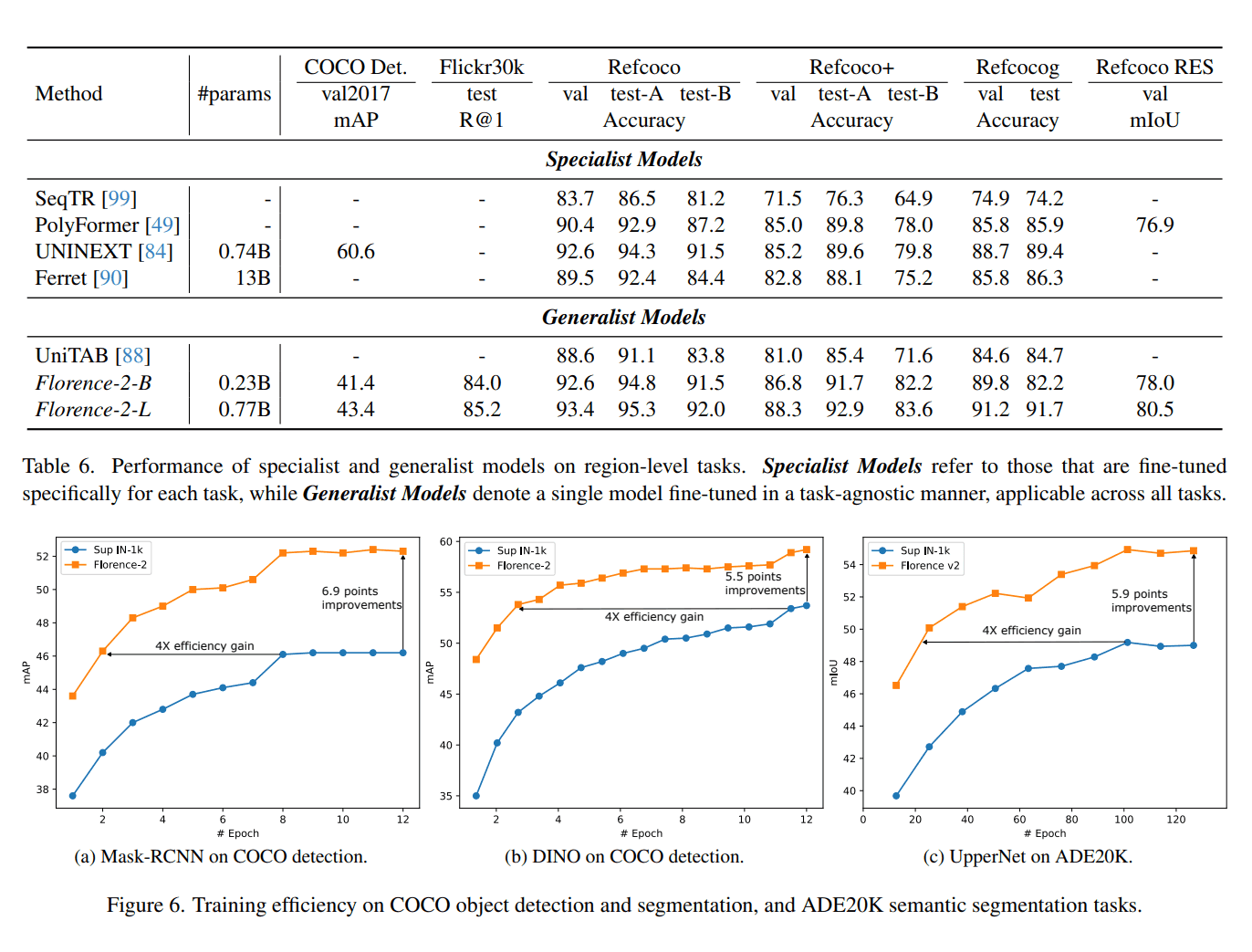
Conclusion: Envisioning the Future with Florence-2
Florence-2, with its innovative approach and the extensive capabilities demonstrated by the FLD-5B dataset, is redefining the boundaries of vision AI. Its ability to understand and interpret images through a unified approach opens new horizons for AI applications in various industries, making it a pivotal development in the journey of computer vision.



