


In a groundbreaking announcement on September 25th, 2023, OpenAI introduced its advanced model, GPT-4, with two game-changing features: image question answering and speech input capabilities.
Signifying its expansion as a multi-modal model, GPT-4V can process both textual and visual inputs to generate informed responses. This puts it in the league of Microsoft's Bing Chat and Google’s Bard model, which also support image inputs.
But how does GPT-4V fare in real-world tests? Dive in as we reveal our first impressions and hands-on experiments with this new tech sensation.
GPT-4V(ision) At A Glance
A cutting-edge multi-modal model by OpenAI, GPT-4V lets users submit an image and pose a question about it. This interaction model, termed as Visual Question Answering (VQA), is now accessible via the OpenAI ChatGPT iOS app and web interface, contingent on having a GPT-4 subscription.
Decoding GPT-4V's Capabilities:
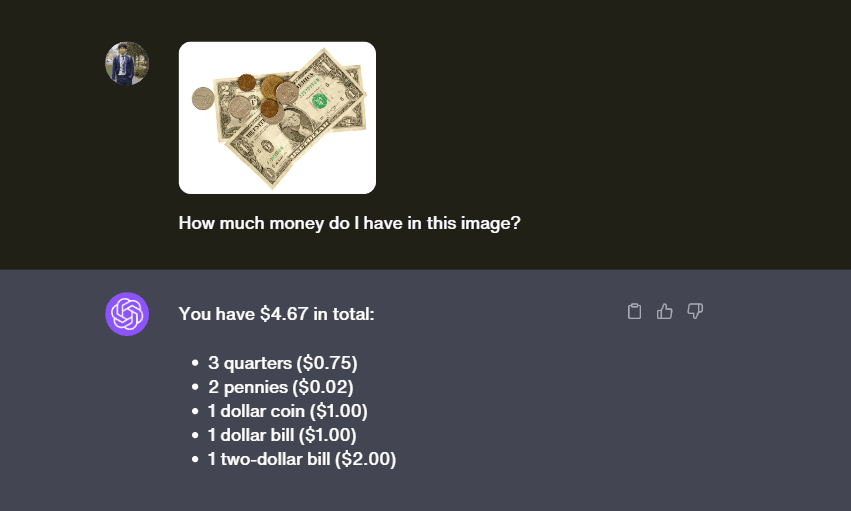
Currency Recognition:
GPT-4V adeptly identified US currency, recognizing quarters, pennies, a dollar bill and even rarer currencies like a one dollar coin and a two dollar bill.
OCR Abilities:
GPT-4V was able to detect the license plate number from a vehicle image, showing its Chat GPT’s new Optical Character Recognition capabilities.

Object Detection:
Next, we tested GPT-4V’s object detection skills. GPT-4V's successfully detected two animals: a cheetah and a gazelle and was able to take it one step further by captioning the image.

Understanding GPT-4V's Limitations:
OpenAI, after rigorous testing, highlights several constraints of GPT-4V, including:
- Inaccuracies in detecting text or mathematical symbols in images
- Difficulty in recognizing spatial aspects and colors
- Steering clear of identifying specific persons in images
- Avoiding hate symbol prompts
However, some risks remain, as highlighted by OpenAI's system card, necessitating continued research and mitigation efforts.
GPT-4V: A Leap in Computer Vision
GPT-4V represents a significant stride in machine learning and NLP. The ability to question images directly, followed by in-depth, contextual answers, makes GPT-4V truly revolutionary. Its responsiveness and context-awareness, like identifying a movie from an image, set it apart from its predecessors. Yet, like all innovations, GPT-4V isn't without its challenges. Some inaccuracies or "hallucinations" and its current ineptitude in precise object detection underscore the importance of understanding its boundaries.
While GPT-4V still underperforms in accuracy, it has undoubtedly reshaped the landscape of visual interaction, promising an exciting future for ChatGPT and GPT vision applications.
Looking to effortlessly integrate high accuracy Computer Vision in your application? Explore ezML's platform and deploy pre-built models with just an API call. We offer:
- general object detection
- optical character recognition (OCR)
- face recognition
- Image Captioning
- Generative Imaging
- Image Upscaling, etc
Try it now with 2500 free credits!



