


Microsoft’s Phi-3.5 Vision Model: Redefining Multimodal AI
Microsoft's Phi-3.5 Vision is a lightweight, multimodal AI model designed for environments with limited memory and computational resources. It excels in complex visual reasoning, offering cutting-edge capabilities in image understanding, optical character recognition (OCR), and multi-image comparison.
Multimodal Integration: Seamlessly processes text and visual inputs for applications requiring contextual understanding between images and text.
Extended Context Length: Supports 128K tokens, allowing it to handle long sequences of text and images without losing coherence.
Technical Architecture: The Backbone of Phi-3.5 Vision
The Phi-3.5 Vision model is built on a robust architecture designed for optimal performance in memory-constrained environments.
Image Encoder: Converts images into a format that integrates with text data.
Connector: Bridges the image encoder and language model for cohesive data processing.
Projector: Maps visual data into the same space as the language model.
Phi-3 Mini Language Model: Processes text and generates responses based on visual and textual inputs.
Training and Data Sources: Ensuring High-Quality Outputs
Phi-3.5 Vision was trained using a meticulously curated dataset, ensuring the model delivers high-quality, reasoning-dense outputs.
Diverse Data Sources: Includes synthetic data, high-quality educational content, and rigorously filtered public documents.
Supervised Fine-Tuning: Enhances instruction adherence and output reliability.
Optimization: Incorporates direct preference optimization for improved performance.
Benchmark Performance: Leading the Pack
On average, phi 3.5 outperforms competitor models on the same size and competitive with much bigger models on multi-frame capabilities and video summarization.
BLINK: a benchmark with 14 visual tasks that humans can solve very quickly but are still hard for current multimodal LLMs.

Phi-3.5 Vision has demonstrated exceptional performance in various benchmarks, solidifying its position as a leader in multimodal AI.
MMMU Benchmark: Improved performance from 40.2 to 43.0.
TextVQA Benchmark: Increased accuracy from 70.9 to 72.0.
Multi-Image and Video Summarization: Outperformed competitor models in handling complex visual data.
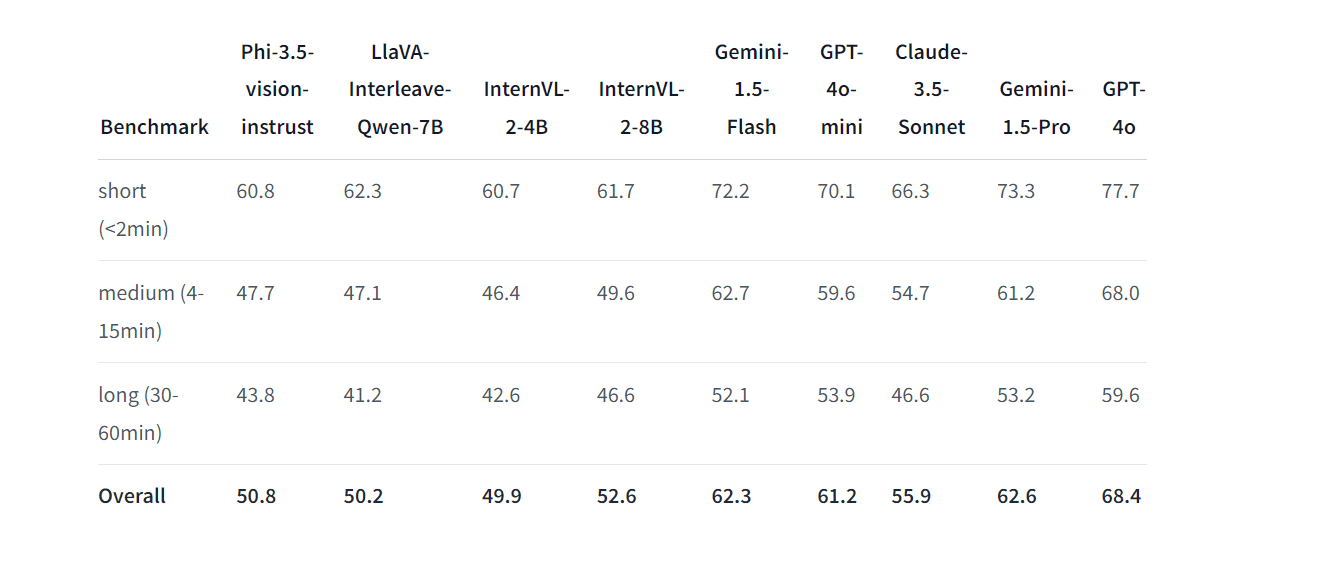
Here was another benchmark on processing video data called Video-MME:
Use Cases: Versatile Applications
Phi-3.5 Vision's capabilities make it ideal for a wide range of applications, particularly in resource-constrained environments.
Optical Character Recognition (OCR): Automates data extraction from images and documents.
Chart and Table Understanding: Analyzes complex visual data for structured insights.
Multi-Image Comparison: Identifies patterns and differences across multiple images.
Video Summarization: Extracts key frames and generates coherent narratives from video clips.
A New Era of Lightweight Multimodal AI
Microsoft’s Phi-3.5 Vision model redefines what’s possible in multimodal AI with its lightweight design and powerful visual reasoning capabilities. Its open-source nature makes it accessible for innovation in both commercial and research settings, setting a new standard for AI performance in resource-constrained environments.
Demo & API Acesss
Gradio Demo: https://huggingface.co/spaces/MaziyarPanahi/Phi-3.5-Vision
To request API access, feel free to pick one of the options:
Book a meeting with our team for a free computer vision consultaiton
Join our discord and ask in #general
Email us at admin@ezml.io



